Speeding It Up With llama.cpp
For Part 2, I'm looking at running Qwen 3 with llama.cpp. You can find Part 1 here.
I'm trying out the new model and llama.cpp should give a sizable boost in performance over Ollama. It is implemented in C/C++ and according to their docs, "Apple silicon is a first-class citizen".
I am running on a MacBook Pro with a M3 Max and 36GB of memory.
Setup
Tools
- llama.cpp - Downloads and runs the AI models
- Continue.dev - A platform to connect the IDE to the running Ollama models
- Visual Studio Code as my IDE with the Continue extension
- Model used: Qwen3-Coder-30B-A3B-Instruct
Getting Started
Getting the model running was pretty simple. I installed the llama.cpp CLI tools and then had to find a GGUF. I ended up going with unsloth's Qwen3-Coder-30B-A3B-Instruct-GGUF. I chose the 4 bit quantization model.
llama-server \
-hf unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF:Q4_K_XL \
--jinja -ngl 99 --threads -1 --ctx-size 32684 \
--temp 0.7 --min-p 0.0 --top-p 0.8 --top-k 20 --mlock --repeat-penalty 1.05After some small changes to the Continue.dev config, I started it up and immediately noticed an improvement in the response speed.
Let's Make Something
Flappy Bird
I wanted to test how it would do on a fresh prompt so I had it create flappy bird in JavaScript with no extra tools. It worked! And even better, it worked in a reasonable amount of time.

I forgot how difficult this game is! This was a fun little test, but now let's go back to the original project - the Hiragana Quiz.
Back to the Quiz
So my next goal for the Hiragana Quiz is to give the user some results. I want an overall score of correct answers on the first guess and perhaps a table showing the number of failed guesses so the user can see what they need to study most.
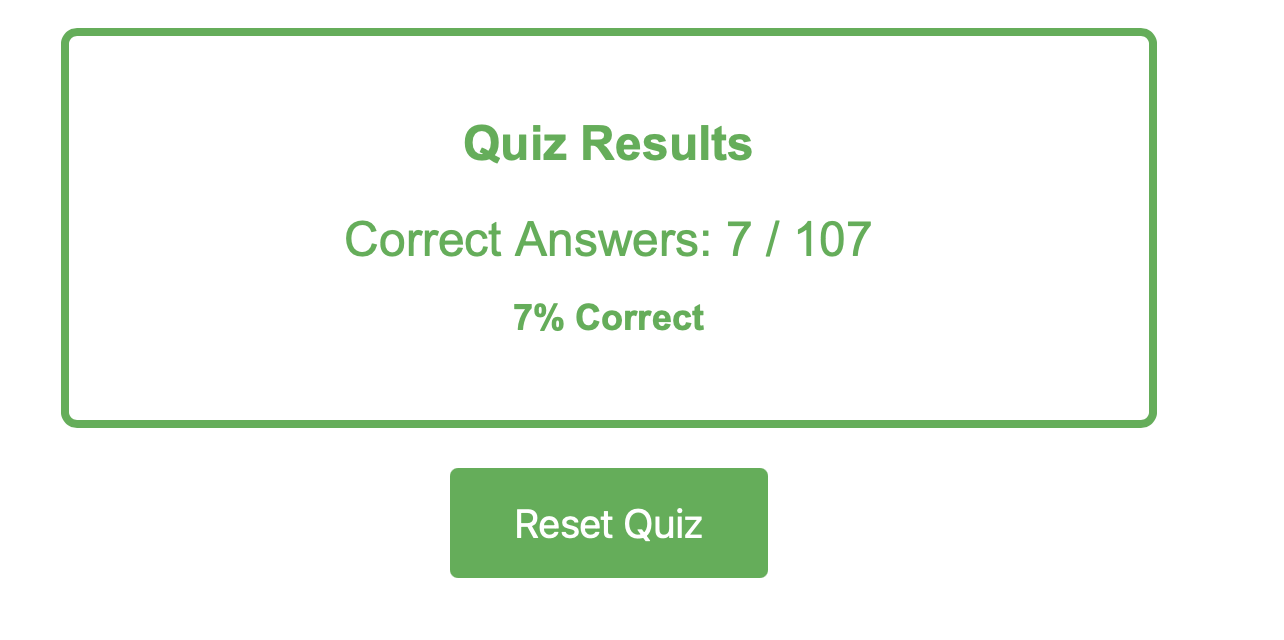
This first attempt went poorly. I think my initial prompt asked for too much with too few specifics and it was all downhill from there. It felt like I was fighting the LLM at every prompt. It was suggesting overly complex code for simple tasks that didn't work and it kept coming back to the same bad ideas. It did make a score screen and a table of guesses. However the score calculations were buggy and it overcomplicated things.
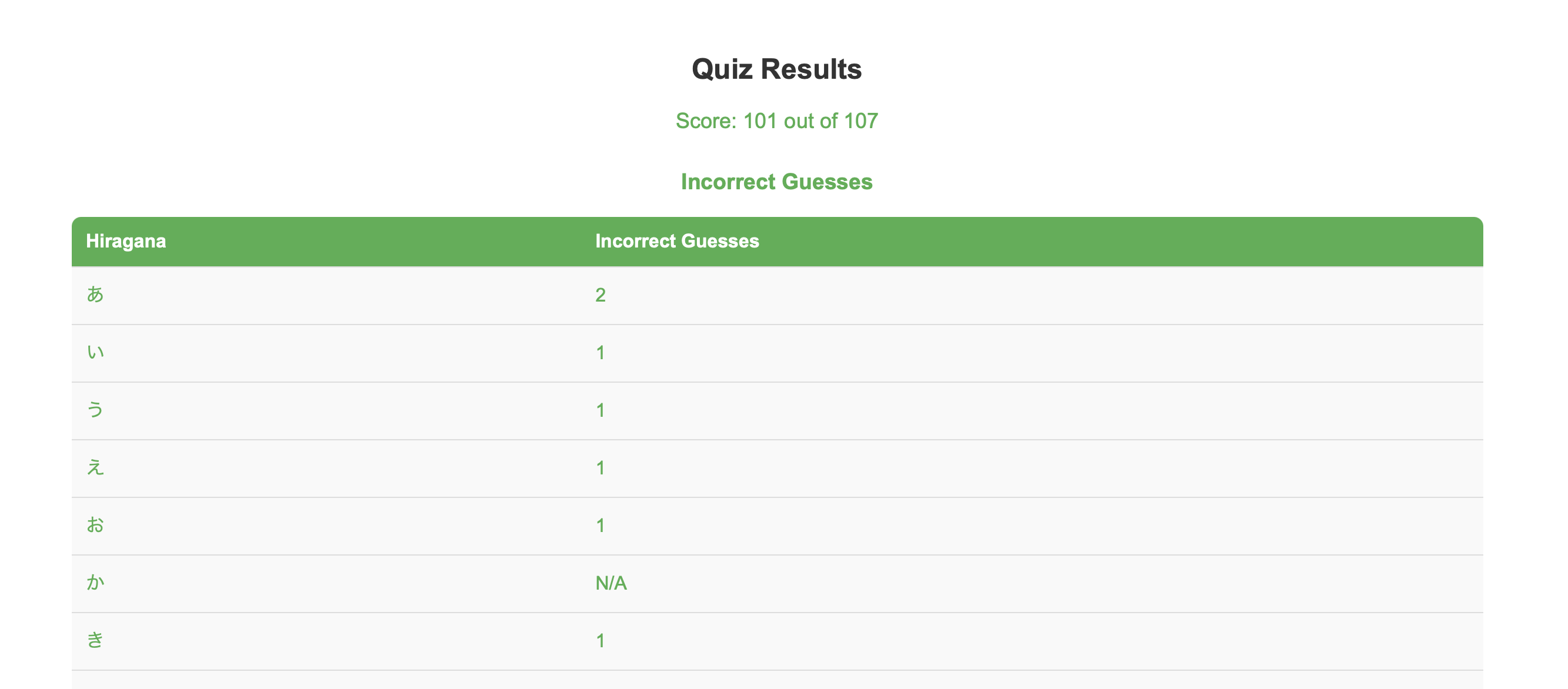
Eventually I gave up and started fresh.
Attempt 2
For the next attempt, I decided to simplify things and focus on showing the user a score after they completed the quiz. With the clean slate, I initialized it with a prompt giving it basic goals and rules. I gave the three files as context and told it that it should use the colors from the stylesheet provided.
I set it off on its first task: adding a button and switching from the quiz to the score view using example data. It added the button and hid the quiz when clicked and created a sample score page. But it gave the score view a display: none and duplicated a handful of CSS classes with different names. I fixed this manually and gave Qwen some new instructions about not duplicating existing CSS classes.
The second task was to calculate the score. It took some iterating and it eventually got there. It added some reasonable styles but then it made a copy of the classes in styles.css and put them into the Vue component... hmmm 🤔. Looking back, perhaps it was missing the context of the Vue app initialization file that imported the stylesheet?
Next I wanted to keep track of the number of attempts and mark the answer as incorrect if it took more than one attempt. The solution had some bugs and was overly complex so I fixed it manually. This is where it got really frustrating. At every prompt after this, Qwen would try to revert my changes and go back to the broken solution. I wasn't even trying to update any of the logic, just how the data was displayed. I wish I had saved the diffs to show you.
With that, I decided it was time to call it a night. Not bad really. And it's kind of fun, even with the frustrations.
Final Thoughts
Successes
- Switching to llama.cpp significantly improved the speed of the model. I was able to run the model as an agent with sufficient speed.
- Configuring the Continue.dev
@Codebasecontext provider helped the model produce better code. - Still having fun and still learning.
Failures
- Adding my own edits would throw Qwen off. I think it loses context and then wants to revert edits I performed manually. Perhaps I could have fixed this with
@Codebase? - Just like Gemini, it creates numerous drive-by edits of CSS that had little to do with the task at hand.
- Also like Gemini, it copied CSS classes and added a new name instead of reusing the existing one.
- It pulled colors out of the air instead of the predefined ones and would duplicate CSS, even after I told it to use the colors already defined.
- It was having trouble with Vue; it kept removing
ref()initializations on variables that need reactivity. It eventually learned, though. - I'm still failing to get
continue.devto use tools properly to run tests or install a package. - Qwen wanted to delete previously implemented features (question order randomization, for example).
- It created plenty of little annoying bugs like adding
display: noneto a new CSS class.
In Conclusion
Overall this was a mild success. Running llama.cpp was a huge improvement but this model just wasn't generating satisfactory results as an agent. And it's working on essentially a blank canvas. I would have finished it faster myself by using Qwen as an autocomplete. Perhaps that is to be expected. I'm still running a small, quantized model. While the speed boost is great, the model left a lot to be desired.
While impressive, as it stands I'll be sticking to other tools for now. It did fine in some tasks but I don't feel like it provided enough value.
Shoot me a message if you have any tips or tricks to get better results with llama.cpp and Qwen 3. I'm sure there are things I can do to improve the results.